Enron dataset is commonly used dataset by scientific community and researchers as a test or training data for various NLP tasks. In this article, we will load this dataset into MongoDB for faster parsing.
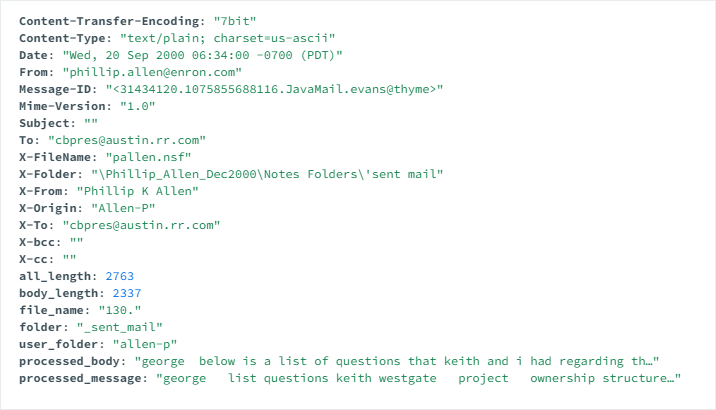
Overview
The Enron Corpus consists of over 600,000 emails generated by 158 employees. [1]
Mails are leading up to the company’s collapse in December 2001 and extracted by Federal Energy Regulatory Commission (FERC) during historical investigation.
A documentary named “Enron: The Smartest Guys in the Room” which produced in 2005 details the time leading up to the downfall of the company.
An online version of the database, which also includes the ability to search e-mails, can be accessed at archive.enron.email address.
When a keyword searched such as Windows its possible to see mails that revealing the software and hardware usage of the company. A software supported by NLP can systematically extract data from dataset. Operation can reveal the technological interpretations and to form an idea about the technological background of the company at the relevant time.
NLP applications can vary according to purpose and use. Its important to note that usage of MongoDB is a design choice have been made for this situation. Whether its a best option or not it is notable when speeding up the process and provide easy accessibility to that version of data.
Within the scope of this article we will get the dataset as a csv file, import it to a MongoDB database, parse it using Python email module and export the result as a seperate csv file.
Parsed data is also shared on Kaggle for later use.
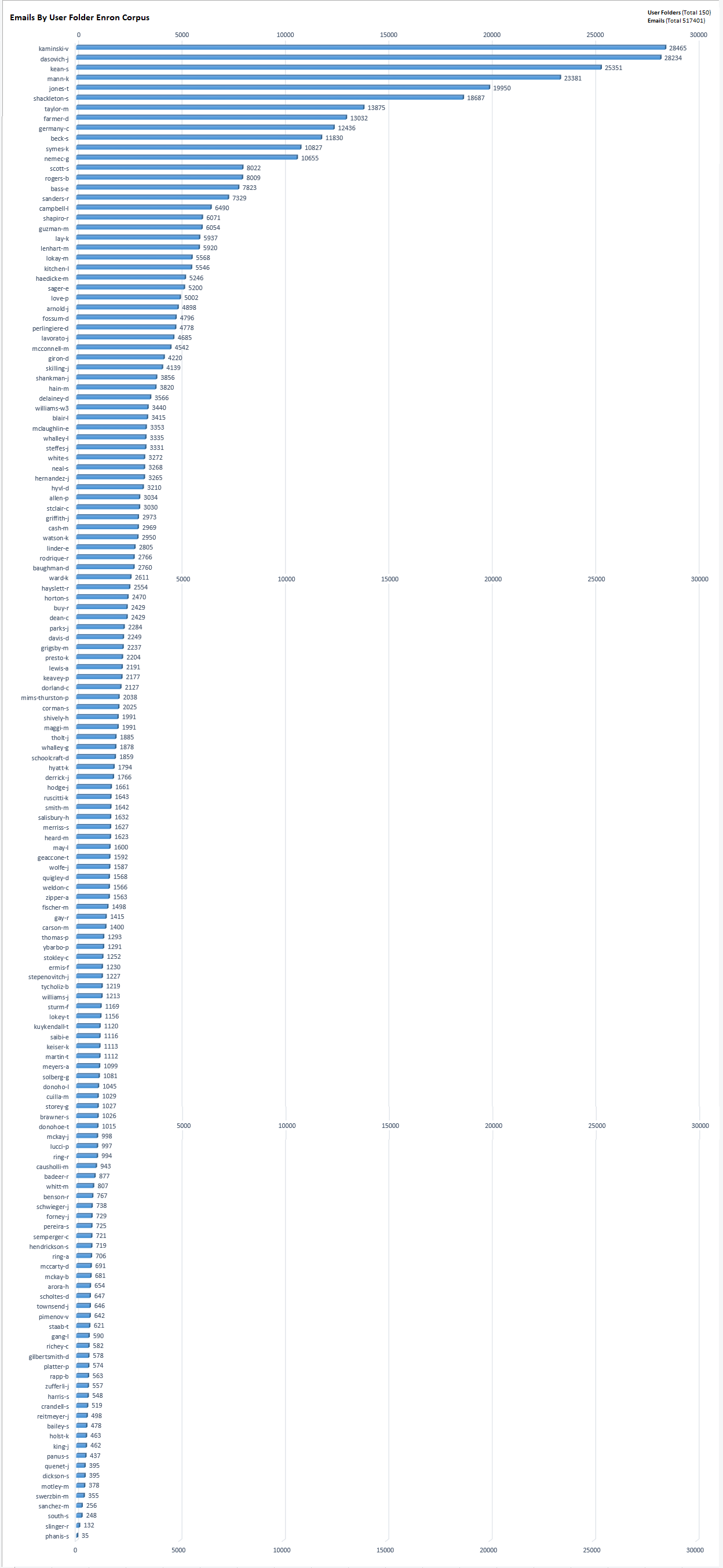
There is also chart created from data:
- Emails By User Chart, data
{kind=link}
1. Getting The Dataset
Its possible to find different versions of Enron dataset on the internet.
The official one May 7, 2015 version of dataset is accessible from here. This version has 517.401 emails belonging 150 employees.
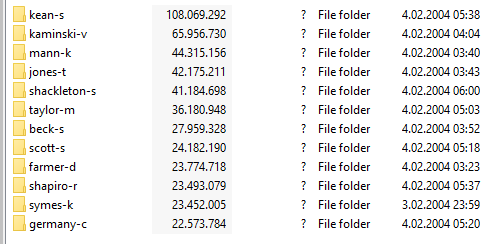
The file enron_mail_20150507.tar.gz tarred and gzipped and it is 422MB in size.
When we open the compressed file, we encounter a folder named maildir with a size of 1.4 GB.
There are 150 folders in total under this folder. It consists of the abbreviations of the names of the employees. For example like benson-r or davis-d.
Under these folders, we see folders such as to_do, tasks, sent_items_, inbox and deleted_items. The names of the folders can vary.
For example, like canada or family.
Kaggle Version
There is a kaggle version of database which is taken from same May 7, 2015 Version of dataset.
This is a single csv file named emails.csv sized 1.43 GB.
This csv file has two columns named file and message. The directory of each file is specified with its text content.
We will do extra parsing (using email module of python) and upload the result to Kaggle.
2. Importing CSV File To MongoDB
Instead of editing the CSV file with Python directly or using a pandas dataframe, we can use a database system like MongoDB.
For this purpose I installed mongodb and import rows of csv file.
First we create Enron database and enrondatabase collection through MongoDBCompass interface.
Second we add an empty document to just see the results. We will delete this empty document and header after.
Make sure database and collection name matches.
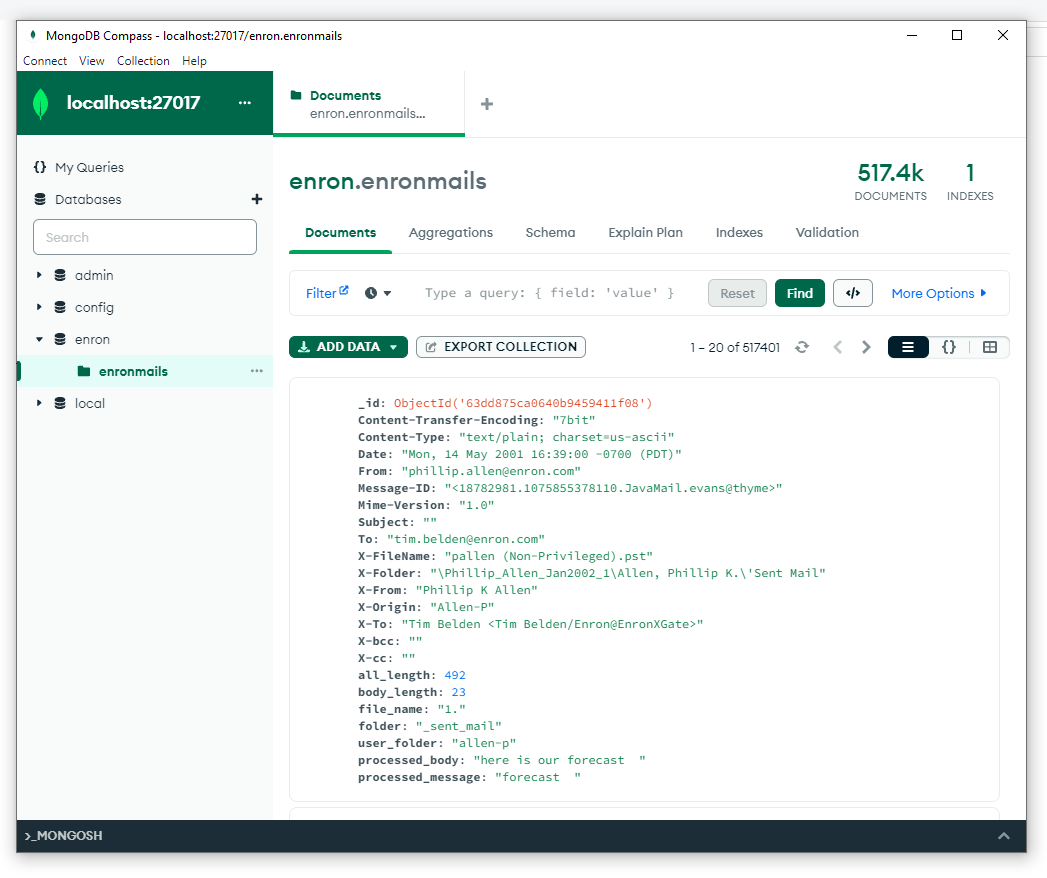
After we create the collection I import email data from a CSV file into a MongoDB database by using a Python script.
When I run the code on my Jupyter notebook instance I can see the inserts from the interface.
Each document should look like this:
{
"_id": {
"$oid": "63e97908c56db67dcfb2308f"
},
"file": "allen-p/_sent_mail/1.",
"message": "Message-ID: <18782981.1075855378110.JavaMail.evans@thyme>\nDate: Mon, 14 May 2001 16:39:00 -070...
}
It takes 3-4 minutes to get all of it by using the code above.
3. Parsing Email Data
I will delete empty document I created and the header. Total document count is 517401 which is a correct number. Now we can do the parsing by calling each document in MongoDB. Make sure database and collection name matches again. We are using Python’s email module to parse headers.
4. Editing Fields
We dont need unparsed “message” field since we have the “body” field. I delete it using query on MongoDB compass interface.
db.enronmails.updateMany({},{$unset: {message:""}})
I change the name of filename field to directory.
db.enronmails.updateMany({},{$rename: {"file":"directory"}})
And I can edit date by using a script similar to one I used before. I will update dates and also parse path names with using this similar script.
The string format of the date in our dataset is called the “rfc2822” format like “Mon, 14 May 2001 16:39:00 -0700 (PDT)”, and it can be parsed using the email.utils module in the Python Standard Library. We use a function that takes a string in this format and returns a string in the universal date format, which is the ISO 8601 format like “2001-05-14T23:39:00”
5. Exporting A Parsed Data
Now I export to new parsed data to use it as a resource for later posts. Also take it as a backup. I also sharing it in Kaggle to speed up for anyone working on dataset.